
- [kubelet-check] Initial timeout of 40s passed.
kubenetes 弃用docker,在V1.24.x版本中kubelet已经不能正常启动了,报这个错切回1.23.x
step1、准备
以下操作在所有节点上同步:
#安装docker
sudo yum install -y yum-utils
sudo yum-config-manager --add-repo https://download.docker.com/linux/centos/docker-ce.repo
sudo yum install -y docker-ce docker-ce-cli containerd.io docker-compose-plugin
#docker镜像加速
curl -sSL https://get.daocloud.io/daotools/set_mirror.sh | sh -s http://f1361db2.m.daocloud.io
sudo systemctl restart docker
#安装docker-compose
curl -L https://get.daocloud.io/docker/compose/releases/download/v2.9.0/docker-compose-`uname -s`-`uname -m` > /usr/local/bin/docker-compose
chmod +x /usr/local/bin/docker-compose
#配置阿里云k8s源
cat <<EOF > /etc/yum.repos.d/kubernetes.repo
[kubernetes]
name=Kubernetes
baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64
enabled=1
gpgcheck=0
repo_gpgcheck=0
gpgkey=https://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg https://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg
EOF
#关闭防火墙
systemctl stop firewalld
systemctl disable firewalld
#关闭selinux 和 swap
sed -i 's/^SELINUX=enforcing$/SELINUX=disabled/' /etc/selinux/config && setenforce 0
swapoff -a
yes | cp /etc/fstab /etc/fstab_bak
cat /etc/fstab_bak |grep -v swap > /etc/fstab
#修改host
cat >> /etc/hosts <<EOF
192.168.148.123 master
192.168.148.124 node
EOF
#修改hostname
hostnamectl set-hostname master
hostnamectl set-hostname node
#安装kubeadm、kubelet、kubectl、kubernetes-cni
yum install -y yum install -y kubelet-1.23.6 kubeadm-1.23.6 kubectl-1.23.6 kubernetes-cni
#启动kubelet服务
systemctl enable docker&& systemctl start docker
systemctl enable kubelet && systemctl start kubelet- 打开kubectl报错
error: no configuration has been provided, try setting KUBERNETES_MASTER environment variable
export KUBECONFIG=/etc/kubernetes/admin.confstep2、启动,部署flannel、ingress-nginx、dashboard、storageclass
使用kubeadm 配置主节点,和pod网络环境,具体参考文档:https://kubernetes.io/zh-cn/docs/setup/production-environment/tools/kubeadm/create-cluster-kubeadm/
kubeadm init --apiserver-advertise-address=192.168.148.123 --image-repository registry.aliyuncs.com/google_containers --kubernetes-version v1.23.6 --pod-network-cidr=10.244.0.0/16 --service-cidr=10.96.0.0/12- [root@192 ~]# kubeadm init --apiserver-advertise-address=192.168.148.123 --image-repository registry.aliyuncs.com/google_containers --pod-network-cidr=10.2.0.0/16 --service-cidr=10.5.0.0/16
[init] Using Kubernetes version: v1.24.4
[preflight] Running pre-flight checks
[WARNING Swap]: swap is enabled; production deployments should disable swap unless testing the NodeSwap feature gate of the kubelet
error execution phase preflight: [preflight] Some fatal errors occurred:
[ERROR CRI]: container runtime is not running: output: E0819 02:58:17.628357 73601 remote_runtime.go:925] "Status from runtime service failed" err="rpc error: code = Unimplemented desc = unknown service runtime.v1alpha2.RuntimeService"
time="2022-08-19T02:58:17-07:00" level=fatal msg="getting status of runtime: rpc error: code = Unimplemented desc = unknown service runtime.v1alpha2.RuntimeService"
, error: exit status 1
[preflight] If you know what you are doing, you can make a check non-fatal with--ignore-preflight-errors=...
To see the stack trace of this error execute with --v=5 or higher
初始化报错,删除containerd 并重启,重新执行kubeadm init
rm -rf /etc/containerd/config.toml
systemctl restart containerd- Failed to run kubelet" err="failed to run Kubelet: misconfiguration: kubelet cgroup driver: \"systemd\" is different from docker cgroup driver:
因为 k8s 和docker 的 cgroup driver 不一致导致的。
k8s 的是 systemd ,而 docker 是cgroupfs。
修改docker配置 , vi /etc/docker/daemon.json
{"registry-mirrors": ["http://f1361db2.m.daocloud.io"],
"exec-opts": ["native.cgroupdriver=systemd"]
}step3、添加工作节点
kubeadm join x.x.x.x:8888 --token xx --discovery-token-ca-cert-hash xx- [ERROR FileContent--proc-sys-net-ipv4-ip_forward]: /proc/sys/net/ipv4/ip_forward contents are not set to 1
#修改配置
echo "1" >/proc/sys/net/bridge/bridge-nf-call-iptables- KubeletNotReady runtime network not ready: NetworkReady=false reason:NetworkPluginNotReady message:docker: network plugin is not ready: cni config uninitialized
kubectl apply -f "https://cloud.weave.works/k8s/net?k8s-version=$(kubectl version | base64 | tr -d '\n')"
# 如果上面种不行就用下面命令安装
$ curl -L git.io/weave -o /usr/local/bin/weave
$ chmod a+x /usr/local/bin/weave
$ weave version- [root@192 ~]# kubeadm init --apiserver-advertise-address=192.168.148.123 --image-repository registry.aliyuncs.com/google_containers --pod-network-cidr=10.2.0.0/16 --service-cidr=10.5.0.0/16
W0819 05:48:49.911027 88169 version.go:103] could not fetch a Kubernetes version from the internet: unable to get URL "https://dl.k8s.io/release/stable-1.txt": Get "https://dl.k8s.io/release/stable-1.txt": EOF
W0819 05:48:49.911109 88169 version.go:104] falling back to the local client version: v1.24.4
[init] Using Kubernetes version: v1.24.4
[preflight] Running pre-flight checks
error execution phase preflight: [preflight] Some fatal errors occurred:
[ERROR FileAvailable--etc-kubernetes-manifests-kube-apiserver.yaml]: /etc/kubernetes/manifests/kube-apiserver.yaml already exists
[ERROR FileAvailable--etc-kubernetes-manifests-kube-controller-manager.yaml]: /etc/kubernetes/manifests/kube-controller-manager.yaml already exists
[ERROR FileAvailable--etc-kubernetes-manifests-kube-scheduler.yaml]: /etc/kubernetes/manifests/kube-scheduler.yaml already exists
[ERROR FileAvailable--etc-kubernetes-manifests-etcd.yaml]: /etc/kubernetes/manifests/etcd.yaml already exists
意外中断或者出错导致未启动成功,执行
kubeadm reset,并重新init- 重启虚拟机后dashboard的pod状态为CrashLoopBackOff ,查看日志集群ip不通 Get "https://10.5.0.1:443/api/v1/namespaces/kubernetes-dashboard/secrets/kubernetes-dashboard-csrf": dial tcp 10.5.0.1:443: i/o timeout
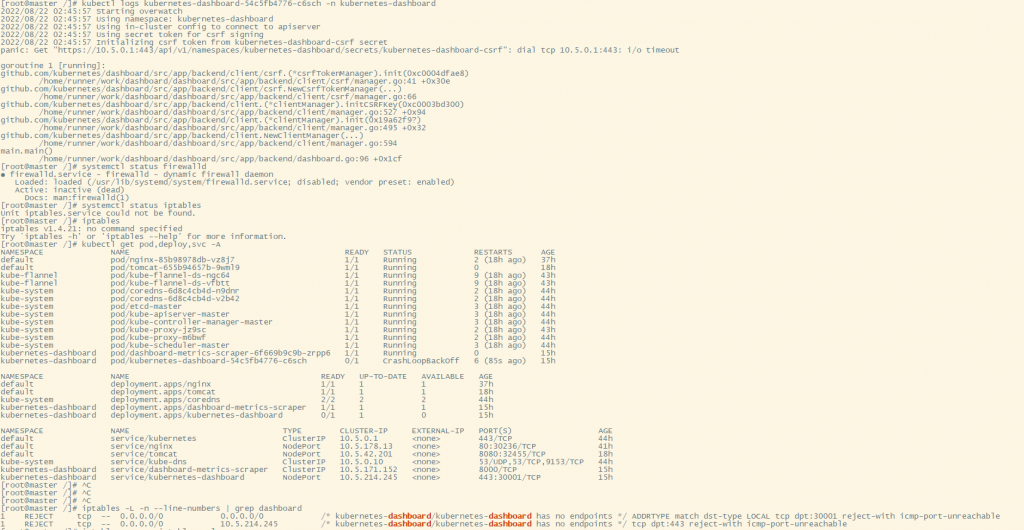
查看iptables规则,iptables -L -n --line-numbers | grep dashboard
1)先把现有的防火墙规则保存下
iptables-save > iptables.rules
2)执行以下命令以确保默认策略为ACCEPT
iptables -P INPUT ACCEPT
iptables -P FORWARD ACCEPT
iptables -P OUTPUT ACCEPT
3)执行下命令:iptables -F
4)把创建的dashboard pod删掉并重启下docker,再次创建dashboard,创建成功
- ingress-nginx 镜像无法下载,kubectl apply -f https://raw.githubusercontent.com/kubernetes/ingress-nginx/controller-v1.3.0/deploy/static/provider/baremetal/deploy.yaml
... image: registry.k8s.io/ingress-nginx/controller:v1.3.0@sha256:d1707ca76d3b044ab8a28277a2466a02100ee9f58a86af1535a3edf9323ea1b5 修改为hub镜像地址 anjia0532/google-containers.ingress-nginx.controller:v1.3.0 https://hub.docker.com/r/anjia0532/google-containers.ingress-nginx.controller/tags
k8s意外死机关机停电,导致起不来,systemctl status kubelet 发现Error getting node" err="node \"k8s-master\" not found,排查发现 docker ps -aq 大部分k8s组件启动不正常,查看apiserver服务容器的启动日志, 发现又出现报错Error while dialing dial tcp 127.0.0.1:2379: connect: connection refused,2379是etcd的端口,那么apiserver是由于etcd无法连接而启动不了,出现错误:
- [WARNING] Deprecated '--logger=capnslog' flag is set; use '--logger=zap' flag instead
- 2022-08-26 14:18:17.857604 I | embed: peerTLS: cert = /etc/kubernetes/pki/etcd/peer.crt, key = /etc/kubernetes/pki/etcd/peer.key, trusted-ca = /etc/kubernetes/pki/etcd/ca.crt, client-cert-auth = true, crl-file =
- 2022-08-26 14:18:17.857997 I | embed: name = k8s-master
- 2022-08-26 14:18:17.858014 I | embed: data dir = /var/lib/etcd
- 2022-08-26 14:18:17.858019 I | embed: member dir = /var/lib/etcd/member
- 2022-08-26 14:18:17.858021 I | embed: heartbeat = 100ms
- 2022-08-26 14:18:17.858022 I | embed: election = 1000ms
- 2022-08-26 14:18:17.858023 I | embed: snapshot count = 10000
- 2022-08-26 14:18:17.858028 I | embed: advertise client URLs = https://192.168.148.120:2379
- 2022-08-26 14:18:17.858030 I | embed: initial advertise peer URLs = https://192.168.148.120:2380
- 2022-08-26 14:18:17.858032 I | embed: initial cluster =
- 2022-08-26 14:18:17.911383 I | etcdserver: recovered store from snapshot at index 30003
- 2022-08-26 14:18:17.913274 C | etcdserver: recovering backend from snapshot error: failed to find database snapshot file (snap: snapshot file doesn't exist)
- panic: recovering backend from snapshot error: failed to find database snapshot file (snap: snapshot file doesn't exist)
- panic: runtime error: invalid memory address or nil pointer dereference
- [signal SIGSEGV: segmentation violation code=0x1 addr=0x20 pc=0xc0587e]
确认是etcd备份数据损坏导致启动故障,在故障节点上停止etcd服务并删除损坏的 etcd 数据,现在etcd服务本来就没有启动,删除前先备份数据,最后启动etcd服务
rm -rf /var/lib/etcd/member,手动启动所有docker组件即可
- 3 pod has unbound immediate PersistentVolumeClaims
在K8S 1.20版本中,弃用了SelfLink这个field,而此版本的nfs-client使用的是旧版本的client-go客户端,无法兼容,从而导致provision失败。
对于这个问题,暂时可选择以下两种之一的解决办法:
1、编辑/etc/kubernetes/manifests/kube-apiserver.yaml文件,在command增加--feature-gates=RemoveSelfLink=false,将SelfLink重新启用。保存文件后等待kube-apiserver重启即可。
2、修改nfs-client的deployment参数:
kubectl -n kube-system edit deploy 将其中的.spec.template.spec.containers[0].image参数修改为:k8s.gcr.io/sig-storage/nfs-subdir-external-provisioner:v4.0.2
等待nfs-client pod启动即可。
PVC应该很快能成功绑定PV,然后Prometheus也能启动成功。

Comments | NOTHING